2025年度第8回坊っちゃん講座「人間共生型ロボットの現在・過去・未来」開催報告
10月25日(土)に2025年度第8回坊っちゃん講座をオンラインで開催し、80名を超える参加者がありました。
本講座は最先端の研究や応用研究において世界をリードしている研究者が研究の面白さを高校生、中学生および大学生に伝え、勉学意欲の向上と進路選択に資するために開講しています。
今回は、工学部 機械工学科 橋本 卓弥 准教授に講演いただきました。
初めに自己紹介として、子供の頃、母親から高村光太郎の『道程』を読み聞かせられ、今の自分を形作っている原点になったとのお話しがありました。
次に、機械工学とは? の説明があり、「熱力学」「流体力学」「材料力学」「機械力学」の四大力学と「設計・製法」を基礎として、自動車や航空機、ロボットやコンピューター、発電プラントや石油精製プラントなど、あらゆる工業製品・設備・機械システムを開発・設計・製造するための学識と技術を体系づけた学問であるとの説明がありました。
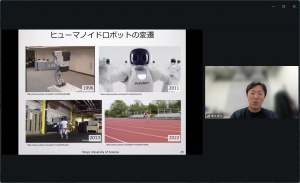
続いて講演では、ヒューマノイドロボットの変遷について、1973年、早稲田大学の加藤一郎教授による世界初の二足歩行ロボット「WABOT-1」の開発から、Hondaの「ASIMO」まで、日本が世界をリードしてきましたが、その後はアメリカ、最近では中国の勢いが凄まじいとのお話しがありました。
近年、技術発展の裏には、AI(人口知能)とロボットの組み合わせにより、色々な作業が出来るようになったことが関係しています。
※AI(人口知能)× ロボット
◎基盤モデル(Foundation Model)
・1つのAIで言葉・画像・音声・動画などの多様な情報をまとめて学習可能
・これまでのAIは特定の作業だけ(翻訳,囲碁,顔認識など)
・ChatGPTやGemini などは言葉・絵・音を統合して理解
◎VLM(Vision Language Model)
・画像(Vision)と言葉(Language)を結びつけて学習するAI
・画像を「見て」「説明する」ことができる
・人間のように「見て考える」AIのベース技術(GPT-4V,Gemini, CLIPなど)
◎VLA(Vision Language Action Model)
・画像と言葉に加えて行動(Action)も結び付けて学習するAI
・人間の命令を理解して,画像から行動を生成
・RT-2,π0などが有名
今後のAIロボットの挑戦として、『感情の理解・共感』『倫理的判断』『身体的経験に基づく理解(身体性)』『意識・目的・意図』『未知の状況への柔軟対応』を挙げ、さらに、現在人間が得意な分野を克服した時、未来はどうなっているのか。
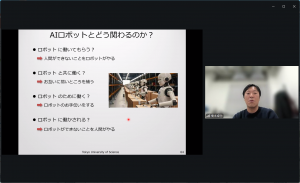
最後に、将来AIロボットとどのように関わるのかを次のように示し、講演を締め括りました。
*ロボットに働いてもらう? ⇒ 人間ができないことをロボットがやる
*ロボットと共に働く? ⇒ お互いに弱いところを補う
*ロボットのために働く? ⇒ ロボットのお手伝いをする
*ロボットに働かされる? ⇒ ロボットができないことを人間がやる
講演後、参加者から届いた多くの質問に橋本先生が1つ1つ丁寧に回答してくださいました。
参加者からは、「人間共存型ロボットの歴史で、からくり人形を見て、大変懐かしく感じました。過去から現代に至り、他国の勢いは国の予算のかけ方が違う、等、この分野は今後著しく伸びて欲しいので、予算を付けて欲しいと素人ながら感じました。同時に、大学に至るまでの間に「興味を抱く」子供たちが育つ環境が必要だと思います。」「AIロボットと人間の得意・不得意な面の比較が理解しやすかった。また、『AIロボットの開発者に必要な、人間の能力の理解・教育』と『一般の人間がAIロボットに負けずに生きていくための、人間の能力を高める教育』の議論がよかった。」「ロボットの進化の歴史や現状の課題などを知ることができてためになりました。また、ロボット工学は、ただ作るだけでなく倫理的に人の心で考えることが大事だとわかり意外と人間らしい学問だと感じました。松田先生のロボットの人間らしさなどについての質問が情緒的親和性を身につけたロボットについて興味があったのでとても共感できました」などの感想が寄せられました。
<講演の様子>